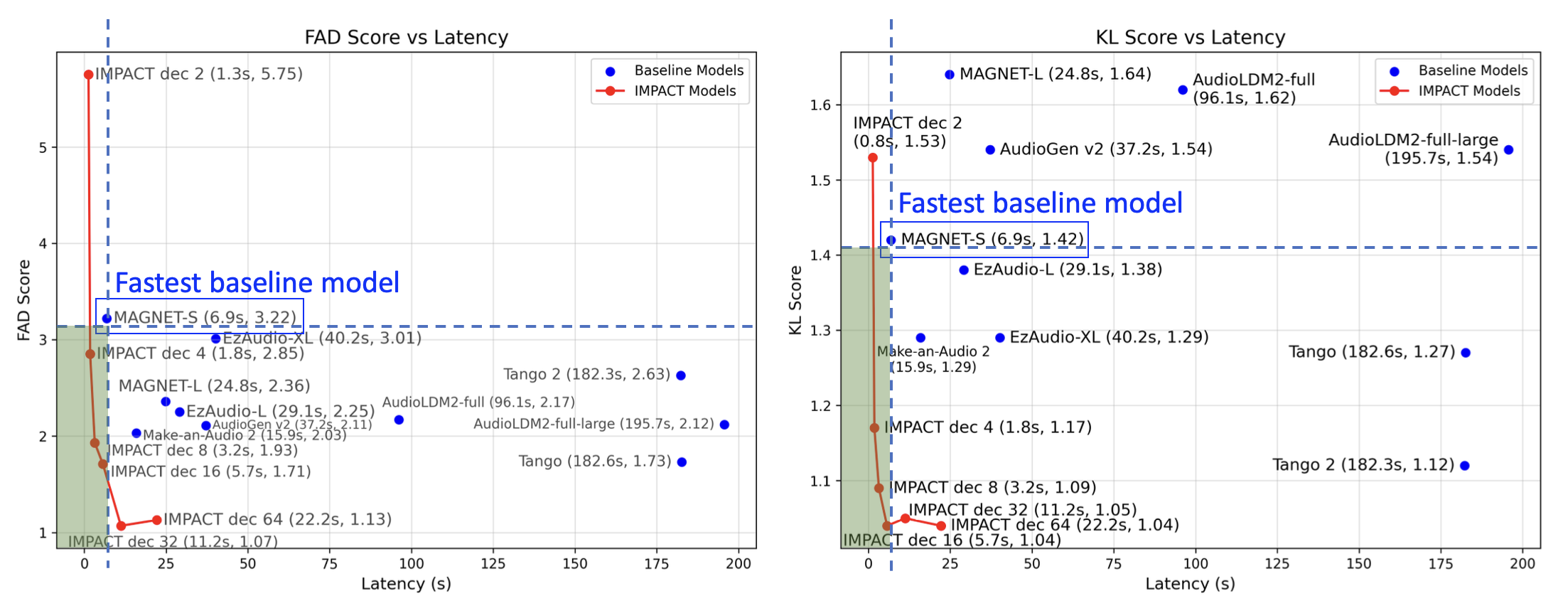
Diagram of IMPACT
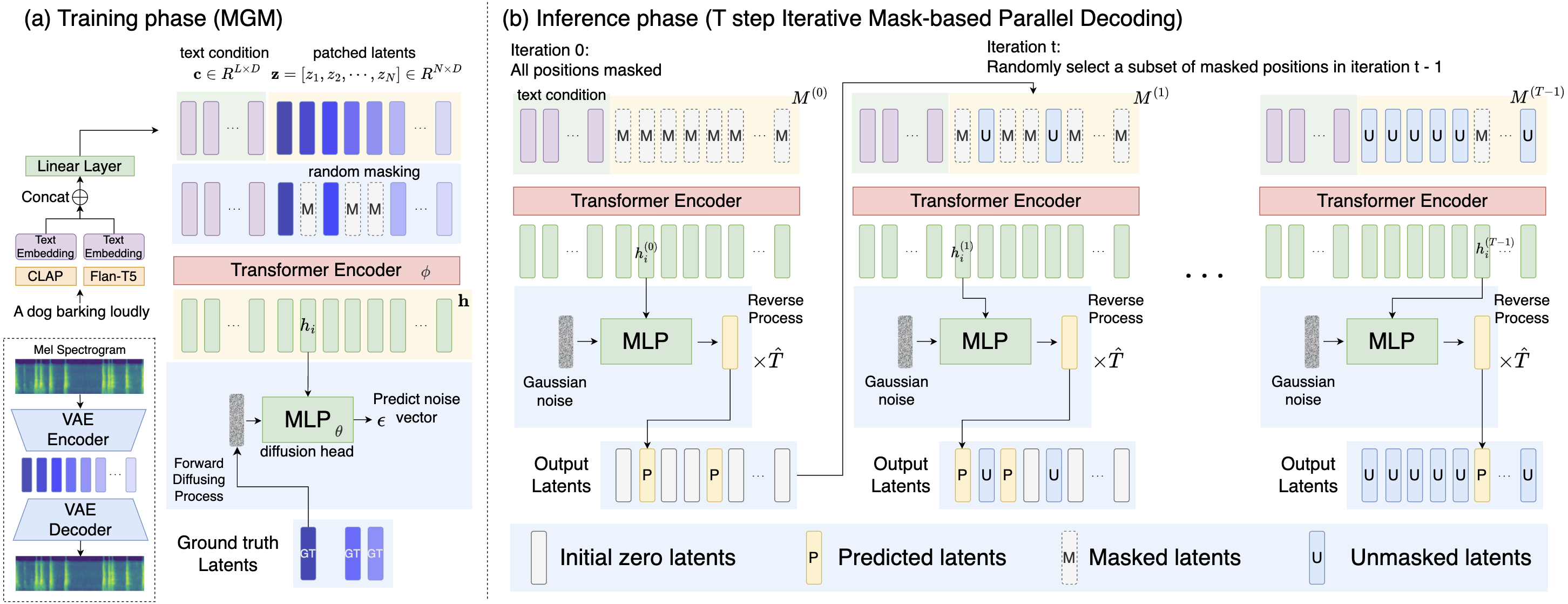
- Training phase: Mask generative modeling
-
Inference phase: Generate a sequence of latents
- A key point here is to gradually generate the sequence throughout an iterative process. In the beginning, the model starts with a sequence with all mask embeddings. At each iteration, a randomly selected portion of positions is predicted and served as the input for the next iteration. The process stops until all positions are predicted.
- The reason for doing so is that latents generated at later iterations can leverage the content predicted in early iterations as conditions.